
Trong thế giới phát triển phần mềm hiện đại, việc ứng dụng Java kết nối và tương tác hiệu quả với cơ sở dữ liệu là một kỹ năng không thể thiếu. Java Database Connectivity (JDBC) API đóng vai trò là cầu nối mạnh mẽ giúp chúng ta thực hiện điều này.

Sau những bài viết trước đó đã khám phá sâu về JDBC và các tính năng quan trọng, hôm nay, tôi sẽ tổng hợp những câu hỏi phỏng vấn JDBC thường gặp nhất cùng với lời giải đáp chi tiết. Bài viết này không chỉ giúp bạn củng cố kiến thức mà còn tự tin hơn khi đối mặt với các buổi phỏng vấn Java, từ đó trang bị nền tảng vững chắc để xây dựng những ứng dụng mạnh mẽ và ổn định.
Các câu hỏi phỏng vấn JDBC thường gặp
1. JDBC API là gì và khi nào chúng ta sử dụng nó?
Java DataBase Connectivity (JDBC) API giúp chúng ta làm việc với các cơ sở dữ liệu quan hệ. Các interface và class của JDBC API thuộc gói java.sql và javax.sql. Chúng ta sử dụng JDBC API để thiết lập kết nối cơ sở dữ liệu, thực thi các truy vấn SQL và stored procedure trên máy chủ cơ sở dữ liệu, sau đó xử lý các kết quả trả về. JDBC API được thiết kế theo cách cho phép kết nối lỏng lẻo (loose coupling) giữa chương trình Java của chúng ta và các driver JDBC thực tế, điều này giúp chúng ta dễ dàng chuyển đổi giữa các máy chủ cơ sở dữ liệu khác nhau.
2. Các loại JDBC Driver khác nhau như thế nào?
Có bốn loại JDBC driver. Bất kỳ chương trình Java nào làm việc với cơ sở dữ liệu đều có hai phần: phần đầu tiên là JDBC API và phần thứ hai là driver thực hiện công việc thực tế.
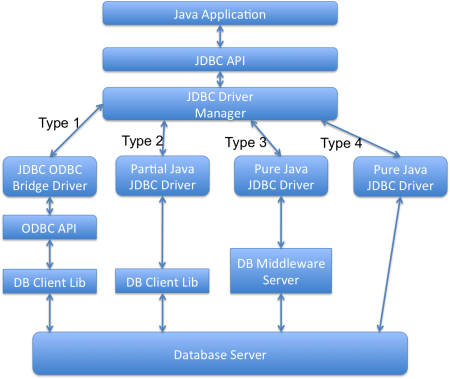
- JDBC-ODBC Bridge cộng với ODBC Driver (Loại 1): Driver này sử dụng ODBC driver để kết nối với cơ sở dữ liệu. Chúng ta cần cài đặt các ODBC driver để kết nối, đó là lý do tại sao driver này gần như đã lỗi thời.
- Native API Driver kết hợp Java (Loại 2): Driver này chuyển đổi các lệnh gọi JDBC sang API client cho các máy chủ cơ sở dữ liệu. Chúng ta cần cài đặt API client của cơ sở dữ liệu. Do có thêm sự phụ thuộc vào các driver API client của cơ sở dữ liệu, driver này cũng không được ưa chuộng.
- Pure Java Driver cho Database Middleware (Loại 3): Driver này gửi các lệnh gọi JDBC đến một máy chủ middleware có thể kết nối với nhiều loại cơ sở dữ liệu khác nhau. Chúng ta cần cài đặt một máy chủ middleware để làm việc với driver này. Điều này làm tăng thêm các lệnh gọi mạng và giảm hiệu suất, đó là lý do tại sao nó không được sử dụng rộng rãi.
- Direct-to-Database Pure Java Driver (Loại 4): Driver này chuyển đổi các lệnh gọi JDBC sang giao thức mạng mà máy chủ cơ sở dữ liệu hiểu được. Giải pháp này đơn giản và phù hợp cho kết nối cơ sở dữ liệu qua mạng. Tuy nhiên, với giải pháp này, chúng ta cần sử dụng các driver cụ thể cho từng cơ sở dữ liệu, ví dụ: các file OJDBC của Oracle cho Oracle DB và MySQL Connector/J cho các cơ sở dữ liệu MySQL.
3. JDBC API giúp đạt được loose coupling giữa chương trình Java và JDBC Drivers API như thế nào?
JDBC API sử dụng Java Reflection API để đạt được sự kết nối lỏng lẻo giữa các chương trình Java và JDBC Drivers. Nếu bạn xem một ví dụ JDBC đơn giản, bạn sẽ nhận thấy rằng tất cả quá trình lập trình đều được thực hiện theo các interface của JDBC API và Driver chỉ xuất hiện khi nó được nạp thông qua reflection bằng phương thức Class.forName().
Đây là một trong những ví dụ tuyệt vời nhất về việc sử dụng Reflection trong các lớp core Java để đảm bảo rằng ứng dụng của chúng ta không làm việc trực tiếp với Driver API, điều này giúp việc chuyển đổi từ cơ sở dữ liệu này sang cơ sở dữ liệu khác trở nên rất dễ dàng.
4. Kết nối JDBC là gì? Hãy giải thích các bước để kết nối cơ sở dữ liệu trong một chương trình Java đơn giản.
JDBC Connection giống như một Session được tạo với máy chủ cơ sở dữ liệu. Bạn cũng có thể hình dung Connection như một kết nối Socket từ máy chủ cơ sở dữ liệu. Việc tạo một JDBC Connection rất dễ dàng và yêu cầu hai bước:
- Đăng ký và Nạp Driver: Sử dụng
Class.forName(), lớp Driver được đăng ký vàoDriverManagervà được nạp vào bộ nhớ. - Sử dụng DriverManager để lấy đối tượng Connection: Chúng ta lấy đối tượng kết nối từ
DriverManager.getConnection()bằng cách truyền chuỗi URL của cơ sở dữ liệu, tên người dùng và mật khẩu làm đối số.
Connection con = null;
try{
// load the Driver Class
Class.forName("com.mysql.jdbc.Driver");
// create the connection now
con = DriverManager.getConnection("jdbc:mysql://localhost:3306/UserDB",
"pankaj",
"pankaj123");
}catch (SQLException e) {
System.out.println("Check database is UP and configs are correct");
e.printStackTrace();
}catch (ClassNotFoundException e) {
System.out.println("Please include JDBC MySQL jar in classpath");
e.printStackTrace();
}
5. Lớp DriverManager trong JDBC có tác dụng gì?
JDBC DriverManager là lớp factory mà thông qua đó chúng ta có được đối tượng Database Connection. Khi chúng ta nạp lớp JDBC Driver, nó tự đăng ký với DriverManager. Bạn có thể xem mã nguồn của các lớp JDBC Driver để kiểm tra điều này. Sau đó, khi chúng ta gọi phương thức DriverManager.getConnection() bằng cách truyền các chi tiết cấu hình cơ sở dữ liệu, DriverManager sử dụng các driver đã đăng ký để lấy Connection và trả về cho chương trình gọi.
6. Làm thế nào để lấy thông tin chi tiết về máy chủ cơ sở dữ liệu trong chương trình Java?
Chúng ta sử dụng đối tượng DatabaseMetaData để lấy thông tin chi tiết về máy chủ cơ sở dữ liệu. Khi kết nối cơ sở dữ liệu được tạo thành công, chúng ta lấy đối tượng meta data bằng cách gọi phương thức getMetaData(). Có rất nhiều phương thức trong DatabaseMetaData mà chúng ta có thể sử dụng để lấy tên sản phẩm cơ sở dữ liệu, phiên bản của nó và các chi tiết cấu hình.
DatabaseMetaData metaData = con.getMetaData();
String dbProduct = metaData.getDatabaseProductName();
7. JDBC Statement là gì?
JDBC Statement được sử dụng để thực thi các truy vấn SQL trong cơ sở dữ liệu. Chúng ta tạo đối tượng Statement bằng cách gọi phương thức createStatement() của Connection. Chúng ta sử dụng Statement để thực thi các truy vấn SQL tĩnh bằng cách truyền truy vấn qua các phương thức thực thi khác nhau như execute(), executeQuery(), executeUpdate() v.v. Vì truy vấn được tạo trong chương trình Java, nếu đầu vào người dùng không được xác thực đúng cách, nó có thể dẫn đến vấn đề tấn công SQL injection. Theo mặc định, chỉ một đối tượng ResultSet trên một đối tượng Statement có thể mở cùng một lúc. Do đó, nếu chúng ta muốn làm việc với nhiều đối tượng ResultSet, thì mỗi đối tượng phải được tạo bởi các đối tượng Statement khác nhau. Tất cả các phương thức execute() trong interface Statement ngầm đóng đối tượng ResultSet hiện tại của một Statement nếu có một đối tượng đang mở.
8. Sự khác nhau giữa execute, executeQuery và executeUpdate là gì?
Statement.execute(String query)được sử dụng để thực thi bất kỳ truy vấn SQL nào và nó trả vềTRUEnếu kết quả là mộtResultSet(ví dụ: khi chạy các truy vấnSELECT). Kết quả làFALSEkhi không có đối tượngResultSet(ví dụ: khi chạy các truy vấnINSERThoặcUPDATE). Chúng ta sử dụnggetResultSet()để lấyResultSetvàgetUpdateCount()để lấy số lượng bản ghi được cập nhật.Statement.executeQuery(String query)được sử dụng để thực thi các truy vấnSELECTvà trả vềResultSet.ResultSettrả về không bao giờ lànullngay cả khi không có bản ghi nào khớp với truy vấn. Khi thực thi các truy vấnSELECT, chúng ta nên sử dụng phương thứcexecuteQueryđể nếu ai đó cố gắng thực thi câu lệnhINSERT/UPDATE, nó sẽ ném rajava.sql.SQLExceptionvới thông báo “executeQuery method cannot be used for update”.Statement.executeUpdate(String query)được sử dụng để thực thi các câu lệnhINSERT/UPDATE/DELETE(DML) hoặc các câu lệnh DDL mà không trả về gì. Kết quả là một giá trịintvà bằng số hàng bị ảnh hưởng đối với các câu lệnh Ngôn ngữ Thao tác Dữ liệu SQL (DML). Đối với các câu lệnh DDL, kết quả là 0.
Bạn chỉ nên sử dụng phương thức execute() khi bạn không chắc chắn về loại câu lệnh, còn lại hãy sử dụng executeQuery hoặc executeUpdate.
9. JDBC PreparedStatement là gì?
Đối tượng JDBC PreparedStatement đại diện cho một câu lệnh SQL đã được biên dịch trước. Chúng ta sử dụng các phương thức setter của nó để thiết lập các biến cho truy vấn. Vì PreparedStatement được biên dịch trước, nó có thể được sử dụng để thực thi câu lệnh này nhiều lần một cách hiệu quả. PreparedStatement là lựa chọn tốt hơn Statement vì nó tự động thoát các ký tự đặc biệt và ngăn chặn các cuộc tấn công SQL injection.
10. Làm thế nào để đặt giá trị NULL trong JDBC PreparedStatement?
Chúng ta sử dụng phương thức PreparedStatement.setNull() để gán biến NULL cho một tham số. Phương thức setNull nhận chỉ số và kiểu SQL làm đối số, ví dụ ps.setNull(10, java.sql.Types.INTEGER);.
11. Phương thức getGeneratedKeys() trong Statement dùng để làm gì?
Đôi khi một bảng có thể có các khóa tự động tạo (auto generated keys) được sử dụng để chèn giá trị cột duy nhất cho khóa chính. Chúng ta sử dụng phương thức Statement.getGeneratedKeys() để lấy giá trị của khóa tự động tạo này.
12. Lợi ích của PreparedStatement so với Statement là gì?
Một số lợi ích của PreparedStatement so với Statement là:
PreparedStatementgiúp chúng ta ngăn chặn các cuộc tấn công SQL injection vì nó tự động thoát các ký tự đặc biệt.PreparedStatementcho phép chúng ta thực thi các truy vấn động với các tham số đầu vào.PreparedStatementnhanh hơnStatement. Điều này trở nên rõ ràng hơn khi chúng ta tái sử dụngPreparedStatementhoặc sử dụng các phương thức xử lý hàng loạt (batch processing) của nó để thực thi nhiều truy vấn.PreparedStatementgiúp chúng ta viết mã hướng đối tượng với các phương thức setter, trong khi vớiStatement, chúng ta phải sử dụng nối chuỗi (String Concatenation) để tạo truy vấn. Nếu có nhiều tham số cần đặt, việc viết truy vấn bằng cách nối chuỗi trông rất xấu và dễ gây lỗi.
13. Hạn chế của PreparedStatement là gì và làm thế nào để khắc phục nó?
Một trong những hạn chế của PreparedStatement là chúng ta không thể sử dụng trực tiếp nó với các câu lệnh IN clause. Một số phương pháp thay thế để sử dụng PreparedStatement với IN clause là:
- Thực thi từng truy vấn riêng lẻ: Rất chậm và không được khuyến nghị.
- Sử dụng Stored Procedure: Phụ thuộc vào cơ sở dữ liệu cụ thể và do đó không phù hợp cho các ứng dụng đa cơ sở dữ liệu.
- Tạo truy vấn PreparedStatement một cách động: Một cách tiếp cận tốt nhưng mất đi lợi ích của
PreparedStatementđã được cache. - Sử dụng NULL trong truy vấn PreparedStatement: Một cách tiếp cận tốt khi bạn biết số lượng đầu vào biến tối đa, có thể mở rộng để cho phép các tham số không giới hạn bằng cách thực thi theo từng phần.
14. JDBC ResultSet là gì?
JDBC ResultSet giống như một bảng dữ liệu đại diện cho một tập kết quả của cơ sở dữ liệu, thường được tạo ra bằng cách thực thi một câu lệnh truy vấn cơ sở dữ liệu. Đối tượng ResultSet duy trì một con trỏ trỏ đến hàng dữ liệu hiện tại của nó. Ban đầu, con trỏ được đặt trước hàng đầu tiên. Phương thức next() di chuyển con trỏ đến hàng tiếp theo. Nếu không còn hàng nào nữa, phương thức next() trả về false và chúng ta sử dụng nó trong vòng lặp while để duyệt qua tập kết quả.
Một đối tượng ResultSet mặc định không thể cập nhật và có một con trỏ chỉ di chuyển về phía trước. Do đó, bạn chỉ có thể lặp qua nó một lần và chỉ từ hàng đầu tiên đến hàng cuối cùng. Có thể tạo các đối tượng ResultSet có thể cuộn (scrollable) và/hoặc có thể cập nhật (updatable) bằng cú pháp dưới đây:
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_UPDATABLE);
Một đối tượng ResultSet tự động đóng khi đối tượng Statement đã tạo ra nó bị đóng, thực thi lại hoặc được sử dụng để truy xuất kết quả tiếp theo từ một chuỗi nhiều kết quả. Chúng ta sử dụng phương thức getter của ResultSet với tên cột hoặc chỉ số cột (bắt đầu từ 1) để truy xuất dữ liệu cột.
15. Các loại ResultSet khác nhau như thế nào?
Có các loại đối tượng ResultSet khác nhau mà chúng ta có được dựa trên đầu vào của người dùng khi tạo Statement. Nếu bạn xem xét các phương thức của Connection, bạn sẽ thấy rằng các phương thức createStatement() và prepareStatement() được nạp chồng (overloaded) để cung cấp kiểu ResultSet và concurrency làm đối số đầu vào. Có ba loại đối tượng ResultSet:
- ResultSet.TYPE_FORWARD_ONLY: Đây là kiểu mặc định và con trỏ chỉ di chuyển về phía trước trong tập kết quả.
- ResultSet.TYPE_SCROLL_INSENSITIVE: Con trỏ có thể di chuyển về phía trước và phía sau, và tập kết quả không nhạy cảm với các thay đổi được thực hiện bởi người khác đối với cơ sở dữ liệu sau khi tập kết quả được tạo.
- ResultSet.TYPE_SCROLL_SENSITIVE: Con trỏ có thể di chuyển về phía trước và phía sau, và tập kết quả nhạy cảm với các thay đổi được thực hiện bởi người khác đối với cơ sở dữ liệu sau khi tập kết quả được tạo.
Dựa trên concurrency, có hai loại đối tượng ResultSet:
- ResultSet.CONCUR_READ_ONLY: Tập kết quả chỉ đọc, đây là kiểu concurrency mặc định.
- ResultSet.CONCUR_UPDATABLE: Chúng ta có thể sử dụng phương thức
updatecủaResultSetđể cập nhật dữ liệu của các hàng.
16. Mục đích của các phương thức setFetchSize() và setMaxRows() trong Statement là gì?
Chúng ta sử dụng phương thức setMaxRows(int i) để giới hạn số lượng hàng mà cơ sở dữ liệu trả về từ truy vấn. Bạn có thể đạt được điều tương tự bằng cách sử dụng chính truy vấn SQL. Ví dụ, trong MySQL, chúng ta sử dụng mệnh đề LIMIT để đặt số hàng tối đa sẽ được truy vấn trả về.
Việc hiểu fetchSize có thể hơi phức tạp, để hiểu rõ hơn, bạn nên biết cách Statement và ResultSet hoạt động. Khi chúng ta thực thi một truy vấn trong cơ sở dữ liệu, kết quả được lấy và duy trì trong bộ đệm của cơ sở dữ liệu và ResultSet được trả về. ResultSet là con trỏ có tham chiếu đến kết quả trong cơ sở dữ liệu. Giả sử chúng ta có một truy vấn trả về 100 hàng và chúng ta đã đặt fetchSize là 10, thì trong mỗi chuyến đi cơ sở dữ liệu, driver JDBC sẽ chỉ tìm nạp 10 hàng và do đó sẽ có 10 chuyến đi để tìm nạp tất cả các hàng.
Việc đặt fetchSize tối ưu rất hữu ích khi bạn cần nhiều thời gian xử lý cho mỗi hàng và số lượng hàng trong kết quả rất lớn. Chúng ta đặt fetchSize thông qua đối tượng Statement nhưng nó có thể bị ghi đè thông qua phương thức setFetchSize() của đối tượng ResultSet.
17. Làm thế nào để sử dụng JDBC API để gọi Stored Procedures?
Stored Procedures là một nhóm các truy vấn SQL được biên dịch trong cơ sở dữ liệu và có thể được thực thi từ JDBC API. JDBC CallableStatement được sử dụng để thực thi các stored procedure trong cơ sở dữ liệu. Cú pháp để khởi tạo CallableStatement là:
CallableStatement stmt = con.prepareCall("{call insertEmployee(?,?,?,?,?,?)}");
stmt.setInt(1, id);
stmt.setString(2, name);
stmt.setString(3, role);
stmt.setString(4, city);
stmt.setString(5, country);
//register the OUT parameter before calling the stored procedure
stmt.registerOutParameter(6, java.sql.Types.VARCHAR);
stmt.executeUpdate();
Chúng ta cần đăng ký các tham số OUT trước khi thực thi CallableStatement.
18. JDBC Batch Processing là gì và lợi ích của nó là gì?
Đôi khi chúng ta cần chạy các truy vấn hàng loạt cùng loại cho một cơ sở dữ liệu. Ví dụ, tải dữ liệu từ các tệp CSV vào các bảng cơ sở dữ liệu quan hệ. Như chúng ta đã biết, chúng ta có tùy chọn sử dụng Statement hoặc PreparedStatement để thực thi các truy vấn.
Ngoài ra, JDBC API cung cấp tính năng Xử lý Hàng loạt (Batch Processing) mà qua đó chúng ta có thể thực thi hàng loạt truy vấn cùng một lúc cho một cơ sở dữ liệu. JDBC API hỗ trợ xử lý hàng loạt thông qua các phương thức addBatch() và executeBatch() của Statement và PreparedStatement. Xử lý hàng loạt nhanh hơn so với việc thực thi từng câu lệnh một vì số lượng lệnh gọi đến cơ sở dữ liệu ít hơn.
19. JDBC Transaction Management là gì và tại sao chúng ta cần nó?
Theo mặc định, khi chúng ta tạo một kết nối cơ sở dữ liệu, nó chạy ở chế độ tự động commit (auto-commit mode). Điều đó có nghĩa là bất cứ khi nào chúng ta thực thi một truy vấn và nó hoàn thành, lệnh commit sẽ được tự động kích hoạt. Vì vậy, mỗi truy vấn SQL chúng ta thực thi là một giao dịch và nếu chúng ta đang chạy một số truy vấn DML hoặc DDL, các thay đổi sẽ được lưu vào cơ sở dữ liệu sau mỗi câu lệnh SQL kết thúc.
Đôi khi chúng ta muốn một nhóm các truy vấn SQL là một phần của một giao dịch để chúng ta có thể commit chúng khi tất cả các truy vấn chạy tốt và nếu chúng ta nhận được một ngoại lệ, chúng ta có thể lựa chọn rollback tất cả các truy vấn đã thực thi như một phần của giao dịch. JDBC API cung cấp phương thức setAutoCommit(boolean flag) mà qua đó chúng ta có thể vô hiệu hóa tính năng tự động commit của kết nối. Chúng ta chỉ nên vô hiệu hóa tự động commit khi cần thiết vì giao dịch sẽ không được commit trừ khi chúng ta gọi phương thức commit() trên connection. Các máy chủ cơ sở dữ liệu sử dụng khóa bảng (table locks) để đạt được quản lý giao dịch và đó là một quá trình tốn nhiều tài nguyên. Vì vậy, chúng ta nên commit giao dịch ngay sau khi hoàn thành.
20. Làm thế nào để rollback một giao dịch JDBC?
Chúng ta sử dụng phương thức rollback() của đối tượng Connection để rollback giao dịch. Nó sẽ hoàn tác tất cả các thay đổi được thực hiện bởi giao dịch và giải phóng bất kỳ khóa cơ sở dữ liệu nào hiện đang được giữ bởi đối tượng Connection này.
21. JDBC Savepoint là gì? Cách sử dụng nó?
Đôi khi một giao dịch có thể là một nhóm nhiều câu lệnh và chúng ta muốn rollback về một điểm cụ thể trong giao dịch. JDBC Savepoint giúp chúng ta tạo các điểm kiểm tra (checkpoints) trong một giao dịch và chúng ta có thể rollback về điểm kiểm tra cụ thể đó. Bất kỳ savepoint nào được tạo cho một giao dịch sẽ tự động được giải phóng và trở nên không hợp lệ khi giao dịch được commit, hoặc khi toàn bộ giao dịch bị rollback. Việc rollback một giao dịch về một savepoint tự động giải phóng và làm cho không hợp lệ bất kỳ savepoint nào khác được tạo sau savepoint đó.
22. JDBC DataSource là gì và lợi ích của nó là gì?
JDBC DataSource là interface được định nghĩa trong gói javax.sql và nó mạnh mẽ hơn DriverManager cho các kết nối cơ sở dữ liệu. Chúng ta sử dụng DataSource để tạo kết nối cơ sở dữ liệu và các lớp triển khai Driver thực hiện công việc thực tế để lấy kết nối. Ngoài việc lấy kết nối cơ sở dữ liệu, DataSource còn cung cấp một số tính năng bổ sung như:
- Caching
PreparedStatementđể xử lý nhanh hơn. - Cài đặt thời gian chờ kết nối (Connection timeout settings).
- Tính năng ghi log (Logging features).
- Ngưỡng kích thước tối đa của
ResultSet. - Tập hợp kết nối (Connection Pooling) trong servlet container sử dụng hỗ trợ JNDI.
23. Làm thế nào để đạt được JDBC Connection Pooling bằng JDBC DataSource và JNDI trong Apache Tomcat Server?
Đối với các ứng dụng web được triển khai trong một servlet container, việc tạo pool kết nối JDBC rất dễ dàng và chỉ liên quan đến vài bước:
- Tạo tài nguyên JDBC JNDI trong các tệp cấu hình của container, thường là
server.xmlhoặccontext.xml. Ví dụ:server.xmlcontext.xml - Trong ứng dụng web, sử dụng
InitialContextđể tra cứu tài nguyên JNDI đã cấu hình ở bước đầu tiên và sau đó lấy kết nối.Context ctx = new InitialContext(); DataSource ds = (DataSource) ctx.lookup("java:/comp/env/jdbc/MyLocalDB");
24. Apache DBCP API là gì?
Nếu bạn sử dụng DataSource để lấy kết nối cơ sở dữ liệu, thông thường mã để lấy kết nối sẽ bị gắn chặt với việc triển khai DataSource cụ thể của Driver. Hơn nữa, hầu hết mã là boilerplate code trừ việc lựa chọn lớp triển khai DataSource. Apache DBCP giúp chúng ta loại bỏ những vấn đề này bằng cách cung cấp triển khai DataSource hoạt động như một lớp trừu tượng giữa chương trình của chúng ta và các driver JDBC khác nhau. Thư viện Apache DBCP phụ thuộc vào thư viện Commons Pool, vì vậy hãy đảm bảo cả hai đều có trong build path.
25. Mức độ cô lập (isolation levels) trong JDBC Connection là gì?
Khi chúng ta sử dụng JDBC Transactions để đảm bảo tính toàn vẹn dữ liệu, DBMS sử dụng các khóa (locks) để chặn quyền truy cập của người khác vào dữ liệu đang được truy cập bởi giao dịch. DBMS sử dụng các khóa để ngăn chặn các vấn đề Dirty Read, Non-Repeatable Reads và Phantom-Read. Mức độ cô lập giao dịch JDBC được DBMS sử dụng để áp dụng cơ chế khóa, chúng ta lấy thông tin mức độ cô lập thông qua phương thức Connection.getTransactionIsolation() và đặt nó bằng phương thức setTransactionIsolation().
| Isolation Level | Transaction | Dirty Read | Non-Repeatable Read | Phantom Read |
|---|---|---|---|---|
TRANSACTION_NONE |
Not Supported | Not Applicable | Not Applicable | Not Applicable |
TRANSACTION_READ_COMMITTED |
Supported | Prevented | Allowed | Allowed |
TRANSACTION_READ_UNCOMMITTED |
Supported | Allowed | Allowed | Allowed |
TRANSACTION_REPEATABLE_READ |
Supported | Prevented | Prevented | Allowed |
TRANSACTION_SERIALIZABLE |
Supported | Prevented | Prevented | Prevented |
26. JDBC RowSet là gì? Có những loại RowSet nào?
JDBC RowSet giữ dữ liệu dạng bảng theo những cách linh hoạt hơn ResultSet. Tất cả các đối tượng RowSet đều được kế thừa từ ResultSet, vì vậy chúng có tất cả các khả năng của ResultSet với một số tính năng bổ sung. Interface RowSet được định nghĩa trong gói javax.sql. Một số tính năng bổ sung được RowSet cung cấp là:
- Hoạt động như Java Beans với các thuộc tính và các phương thức getter-setter của chúng.
RowSetsử dụng mô hình sự kiện JavaBeans và chúng có thể gửi thông báo đến bất kỳ thành phần đã đăng ký nào cho các sự kiện như di chuyển con trỏ, cập nhật/chèn/xóa một hàng và thay đổi nội dung củaRowSet. - Các đối tượng
RowSetmặc định là có thể cuộn và có thể cập nhật, vì vậy nếu DBMS không hỗ trợResultSetcó thể cuộn hoặc có thể cập nhật, chúng ta sử dụngRowSetđể có được các tính năng này.
RowSet được chia thành hai loại chính:
- Connected RowSet Objects: Các đối tượng này được kết nối với cơ sở dữ liệu và giống nhất với đối tượng
ResultSet. JDBC API chỉ cung cấp một đối tượngRowSetđược kết nối làjavax.sql.rowset.JdbcRowSetvà lớp triển khai tiêu chuẩn của nó làcom.sun.rowset.JdbcRowSetImpl. - Disconnected RowSet Objects: Các đối tượng
RowSetnày không yêu cầu kết nối với cơ sở dữ liệu, vì vậy chúng nhẹ hơn và có thể tuần tự hóa (serializable). Chúng phù hợp để gửi dữ liệu qua mạng. Có bốn loại triển khaiRowSetbị ngắt kết nối:- CachedRowSet: Chúng có thể lấy kết nối và thực thi một truy vấn và đọc dữ liệu
ResultSetđể điền dữ liệuRowSet. Chúng ta có thể thao tác và cập nhật dữ liệu khi nó bị ngắt kết nối và kết nối lại với cơ sở dữ liệu để ghi các thay đổi. - WebRowSet (kế thừa từ
CachedRowSet): Chúng có thể đọc và ghi tài liệu XML. - JoinRowSet (kế thừa từ
WebRowSet): Chúng có thể tạoSQL JOINmà không cần phải kết nối với nguồn dữ liệu. - FilteredRowSet (kế thừa từ
WebRowSet): Chúng ta có thể áp dụng tiêu chí lọc để chỉ hiển thị dữ liệu được chọn.
- CachedRowSet: Chúng có thể lấy kết nối và thực thi một truy vấn và đọc dữ liệu
27. Sự khác biệt giữa ResultSet và RowSet là gì?
Các đối tượng RowSet được kế thừa từ ResultSet, vì vậy chúng có tất cả các tính năng của ResultSet với một số tính năng bổ sung. Một trong những lợi ích lớn của RowSet là chúng có thể bị ngắt kết nối (disconnected) và điều đó làm cho nó nhẹ hơn và dễ dàng truyền qua mạng. Việc sử dụng ResultSet hay RowSet phụ thuộc vào yêu cầu của bạn, nhưng nếu bạn định sử dụng ResultSet trong thời gian dài hơn, thì RowSet bị ngắt kết nối là lựa chọn tốt hơn để giải phóng tài nguyên cơ sở dữ liệu.
28. Các ngoại lệ (Exceptions) JDBC phổ biến là gì?
Một số ngoại lệ JDBC phổ biến là:
java.sql.SQLException: Đây là lớp ngoại lệ cơ bản cho các ngoại lệ JDBC.java.sql.BatchUpdateException: Ngoại lệ này được ném ra khi thao tác Batch thất bại, nhưng điều này phụ thuộc vào driver JDBC liệu chúng có ném ra ngoại lệ này haySQLExceptioncơ bản.java.sql.SQLWarning: Dành cho các thông báo cảnh báo trong các thao tác SQL.java.sql.DataTruncation: Khi một giá trị dữ liệu bị cắt cụt bất ngờ vì lý do khác ngoài việc vượt quáMaxFieldSize.
29. Kiểu dữ liệu CLOB và BLOB trong JDBC là gì?
Character Large Objects (CLOBs) là các chuỗi ký tự được tạo thành từ các ký tự một byte với một trang mã (code page) liên quan. Kiểu dữ liệu này phù hợp để lưu trữ thông tin văn bản mà lượng thông tin có thể vượt quá giới hạn của kiểu dữ liệu VARCHAR thông thường (giới hạn trên 32K byte).
Binary Large Objects (BLOBs) là một chuỗi nhị phân được tạo thành từ các byte mà không có trang mã liên quan. Kiểu dữ liệu này có thể lưu trữ dữ liệu nhị phân lớn hơn VARBINARY (giới hạn 32K). Kiểu dữ liệu này tốt để lưu trữ hình ảnh, giọng nói, đồ họa và các loại dữ liệu kinh doanh hoặc ứng dụng cụ thể khác.
30. “Dirty read” trong JDBC là gì? Mức độ cô lập nào ngăn chặn dirty read?
Khi chúng ta làm việc với các giao dịch, có khả năng một hàng được cập nhật và đồng thời, một truy vấn khác có thể đọc giá trị đã cập nhật đó. Điều này dẫn đến một dirty read vì giá trị đã cập nhật chưa phải là vĩnh viễn, giao dịch đã cập nhật hàng có thể rollback về một giá trị trước đó dẫn đến dữ liệu không hợp lệ. Dirty Read được ngăn chặn bởi các mức độ cô lập TRANSACTION_READ_COMMITTED, TRANSACTION_REPEATABLE_READ và TRANSACTION_SERIALIZABLE.
31. Commit hai pha (2-phase commit) là gì?
Khi chúng ta làm việc trong các hệ thống phân tán liên quan đến nhiều cơ sở dữ liệu, chúng ta cần sử dụng giao thức 2 phase commit. Giao thức 2 phase commit là một giao thức cam kết nguyên tử (atomic commitment protocol) cho các hệ thống phân tán. Trong giai đoạn đầu tiên, quản lý giao dịch gửi yêu cầu commit đến tất cả các tài nguyên giao dịch. Nếu tất cả các tài nguyên giao dịch đều OK, quản lý giao dịch sẽ commit các thay đổi của giao dịch cho tất cả các tài nguyên. Nếu bất kỳ tài nguyên giao dịch nào phản hồi là Abort, thì quản lý giao dịch có thể rollback tất cả các thay đổi của giao dịch.
32. Có những loại khóa (locking) nào trong JDBC?
Ở một cấp độ rộng, có hai loại cơ chế khóa để ngăn chặn hỏng dữ liệu do có nhiều hơn một người dùng làm việc với cùng dữ liệu:
- Optimistic Locking: Khóa này được thực hiện bằng mã. Một cột bổ sung được giới thiệu trong bảng để giữ số lần cập nhật. Khi bạn chọn hàng, bạn cũng đọc cột này, ví dụ ‘version’. Bây giờ khi bạn cố gắng cập nhật/xóa hàng, bạn truyền ‘version’ này vào mệnh đề
WHERE. Vì vậy, nếu có các cập nhật từ các luồng khác được thực hiện ở giữa, việc cập nhật sẽ thất bại. Đó là một cách tốt để tránh hỏng dữ liệu nhưng nó có thể dễ gây lỗi nếu ai đó quên cập nhật ‘version’ trong câu lệnh cập nhật của họ. Truy vấn cập nhật trông như thế này với cách khóa này:mysql> update emp SET name = 'David', version = 5 WHERE id = 10 and version = 4; - Pessimistic Locking: Khóa bản ghi từ giai đoạn chọn để đọc, cập nhật và commit. Điều này thường được thực hiện bởi phần mềm nhà cung cấp cơ sở dữ liệu và được kích hoạt bằng cách sử dụng truy vấn
SELECT FOR UPDATE. Cách khóa hàng này có thể dẫn đến hiệu suất chậm và deadlock nếu các luồng giữ khóa trong thời gian dài.
Ngoài ra, một số hệ thống DBMS cung cấp cơ chế khóa để khóa một hàng, bảng hoặc toàn bộ cơ sở dữ liệu.
33. Bạn hiểu gì về các câu lệnh DDL và DML?
Các câu lệnh Data Definition Language (DDL) được sử dụng để định nghĩa lược đồ cơ sở dữ liệu. Các câu lệnh CREATE, ALTER, DROP, TRUNCATE, RENAME thuộc về các câu lệnh DDL và thường chúng không trả về bất kỳ kết quả nào.
Các câu lệnh Data Manipulation Language (DML) được sử dụng để thao tác dữ liệu trong lược đồ cơ sở dữ liệu. SELECT, INSERT, UPDATE, DELETE, CALL v.v. là ví dụ về các câu lệnh DML.
34. Sự khác biệt giữa java.util.Date và java.sql.Date là gì?
java.util.Date chứa thông tin về ngày và giờ, trong khi java.sql.Date chỉ chứa thông tin về ngày, nó không có thông tin về thời gian. Vì vậy, nếu bạn phải giữ thông tin thời gian trong cơ sở dữ liệu, nên sử dụng các trường Timestamp hoặc DateTime.
35. Làm thế nào để chèn một hình ảnh hoặc dữ liệu thô vào cơ sở dữ liệu?
Chúng ta sử dụng kiểu dữ liệu BLOB để chèn hình ảnh hoặc dữ liệu nhị phân thô vào cơ sở dữ liệu.
36. Phantom read là gì và mức độ cô lập nào ngăn chặn nó?
Một phantom read là tình huống mà một giao dịch thực thi một truy vấn nhiều lần và nhận được dữ liệu khác nhau. Giả sử một giao dịch đang thực thi một truy vấn để lấy dữ liệu dựa trên một điều kiện và sau đó một giao dịch khác chèn một hàng khớp với điều kiện đó. Bây giờ khi cùng một giao dịch sẽ thực thi lại truy vấn, một hàng mới sẽ là một phần của tập kết quả. Hàng mới này được gọi là “Phantom Row” và tình huống này được gọi là Phantom Read. Phantom read chỉ có thể được ngăn chặn bằng mức độ cô lập TRANSACTION_SERIALIZABLE.
37. SQL Warning là gì? Làm thế nào để truy xuất các cảnh báo SQL trong chương trình JDBC?
SQLWarning là lớp con của SQLException và chúng ta có thể truy xuất nó bằng cách gọi phương thức getWarnings() trên các đối tượng Connection, Statement và ResultSet. SQL Warnings không dừng việc thực thi script mà cảnh báo người dùng về cảnh báo.
38. Làm thế nào để gọi Oracle Stored Procedure với Database Objects làm IN/OUT?
Nếu Oracle Stored Procedure có các tham số IN/OUT là các Database Objects, thì chúng ta cần tạo một mảng Object cùng kích thước trong chương trình và sau đó sử dụng nó để tạo đối tượng Oracle STRUCT. Sau đó, chúng ta có thể đặt đối tượng STRUCT này cho đối tượng cơ sở dữ liệu bằng cách gọi phương thức setSTRUCT() và làm việc với nó.
39. Khi nào xảy ra lỗi java.sql.SQLException: No suitable driver found?
Bạn nhận được ngoại lệ No suitable driver found khi chuỗi URL SQL không được định dạng đúng cách. Bạn có thể gặp ngoại lệ này trong cả ứng dụng Java đơn giản sử dụng DriverManager hoặc với tài nguyên JNDI sử dụng DataSource. Stack trace của ngoại lệ trông như sau:
org.apache.tomcat.dbcp.dbcp.SQLNestedException: Cannot create JDBC driver of class 'com.mysql.jdbc.Driver' for connect URL ''jdbc:mysql://localhost:3306/UserDB'
at org.apache.tomcat.dbcp.dbcp.BasicDataSource.createConnectionFactory(BasicDataSource.java:1452)
at org.apache.tomcat.dbcp.dbcp.BasicDataSource.createDataSource(BasicDataSource.java:1371)
at org.apache.tomcat.dbcp.dbcp.BasicDataSource.getConnection(BasicDataSource.java:1044)
java.sql.SQLException: No suitable driver found for 'jdbc:mysql://localhost:3306/UserDB
at java.sql.DriverManager.getConnection(DriverManager.java:604)
at java.sql.DriverManager.getConnection(DriverManager.java:221)
at com.journaldev.jdbc.DBConnection.getConnection(DBConnection.java:24)
at com.journaldev.jdbc.DBConnectionTest.main(DBConnectionTest.java:15)
Exception in thread "main" java.lang.NullPointerException
at com.journaldev.jdbc.DBConnectionTest.main(DBConnectionTest.java:16)
Khi gỡ lỗi ngoại lệ này, bạn hãy kiểm tra URL được in trong nhật ký. Như trong nhật ký trên, chuỗi URL là 'jdbc:mysql://localhost:3306/UserDB' trong khi nó phải là jdbc:mysql://localhost:3306/UserDB. (Lưu ý: lỗi thường là dấu nháy đơn thừa hoặc thiếu, hoặc lỗi cú pháp nhỏ trong URL).
40. Cách thực hành tốt nhất trong JDBC là gì?
Một số thực hành tốt nhất trong JDBC là:
- Tài nguyên cơ sở dữ liệu rất nặng, vì vậy hãy đảm bảo bạn đóng chúng ngay khi hoàn thành công việc.
Connection,Statement,ResultSetvà tất cả các đối tượng JDBC khác đều có phương thứcclose()được định nghĩa để đóng chúng. - Luôn đóng
ResultSet,StatementvàConnectionmột cách rõ ràng trong mã, bởi vì nếu bạn đang làm việc trong môi trường pool kết nối, kết nối có thể được trả về pool trong khi để lại các đối tượngResultSetvàStatementđang mở, dẫn đến rò rỉ tài nguyên. - Đóng các tài nguyên trong khối
finallyđể đảm bảo chúng được đóng ngay cả trong trường hợp xảy ra ngoại lệ. - Sử dụng xử lý hàng loạt (batch processing) cho các thao tác hàng loạt cùng loại.
- Luôn sử dụng
PreparedStatementthay vìStatementđể tránh SQL Injection và tận dụng lợi ích biên dịch trước và caching củaPreparedStatement. - Nếu bạn đang truy xuất lượng lớn dữ liệu vào
ResultSet, việc đặt giá trị tối ưu chofetchSizesẽ giúp đạt được hiệu suất tốt. - Máy chủ cơ sở dữ liệu có thể không hỗ trợ tất cả các mức độ cô lập, vì vậy hãy kiểm tra trước khi giả định.
- Các mức độ cô lập nghiêm ngặt hơn dẫn đến hiệu suất chậm, vì vậy hãy đảm bảo bạn đã đặt mức độ cô lập tối ưu cho các kết nối cơ sở dữ liệu của mình.
- Nếu bạn đang tạo kết nối cơ sở dữ liệu trong một ứng dụng web, hãy cố gắng sử dụng tài nguyên JDBC
DataSourcethông qua ngữ cảnh JNDI để tái sử dụng các kết nối. - Cố gắng sử dụng
Disconnected RowSetkhi bạn cần làm việc vớiResultSettrong một thời gian dài.
Kết Luận
Như vậy, qua bài blog này, tôi đã chia sẻ với bạn cái nhìn tổng quan và chi tiết về các câu hỏi phỏng vấn JDBC thiết yếu. Việc nắm vững JDBC không chỉ giúp bạn vượt qua vòng phỏng vấn một cách tự tin mà còn trang bị cho bạn nền tảng vững chắc để xây dựng các ứng dụng Java kết nối cơ sở dữ liệu mạnh mẽ, ổn định và hiệu quả.
Hãy nhớ rằng, lý thuyết luôn đi đôi với thực hành. Bạn nên chủ động viết code, thử nghiệm với các loại driver, quản lý transaction và thực hành các best practices để củng cố kiến thức.